I love automated testing, and I really love Protractor testing. Although Protractor is an e2e testing tool created by Google and popularized on AngularJS projects, I've heard that it was possible to use it with non-Angular sites. When I tried I had a bit of trouble, but in this post I'll show you how I managed to get it working.
Step 1: Set up A Project with Protractor
If you don't know by now, my go-to yeoman generator that I recommend to everyone is Gulp-Angular. This will set you up with protractor testing right out of the box! All you have to do is run this from the command line:
gulp protractor
Step 2: Create a Test Suite
Remember, test suites in JavaScript can be thought of as a "describe full of it's". Our gulp scripts from Gulp-Angular will look for files in our e2e directory that have a .spec.js ending. Here's an example of a simple protractor test suite:
'use strict'; describe('The main view', function () { beforeEach(function () { browser.get('/index'); }); it('should do nothing', function () { }) });
The only thing the above script really does is load up the index page of your application. This is all fine and dandy, but suppose you wanted to run protractor on a random site like www.facebook.com? If we naively just swap out the '/index' with 'http://www.facebook.com' our protractor runner will crash with a message, "Failed: Angular could not be found on the page **: retries looking for angular exceeded". Ouch!
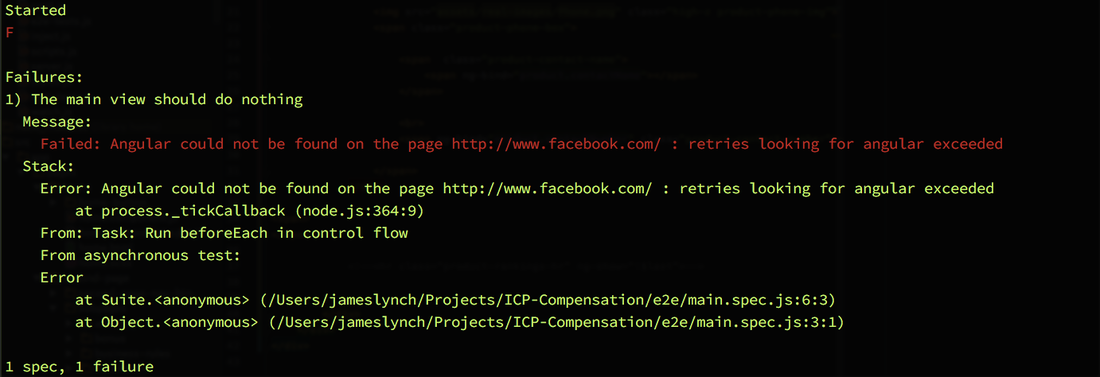
Step 3 (The Aha Moment): Use browser.DRIVER.get
Thanks to the number 1 answer of this stack overflow question, I realized that in order to tell Protractor not to look for Angular you have to load up the page with the underlying web-driver instance. To do this simply use browser.driver.get(...) instead of usual browser.get(...) syntax. The completed suite for testing Facebook with Protractor would look something like this:
'use strict'; describe('The main view', function () { beforeEach(function () { browser.driver.get('http://www.facebook.com'); }); it('should do nothing', function () { }) });


 RSS Feed
RSS Feed